

大家好,今天小编关注到一个比较有意思的话题,就是关于hbase查询需要多久的问题,于是小编就整理了4个相关介绍的解答,让我们一起看看吧。
spark读hbaseparquet哪个快?
spark读hbase,生成task受所查询table的region个数限制,任务数有限,例如查询的40G数据,10G一个region,很可能就4~6个region,初始的task数就只有4~6个左右,RDD后续可以partition设置task数;spark读parquet按默认的bolck个数生成task个数,例如128M一个bolck,差不多就是300多个task,初始载入情况就比hbase快,而且直接载入parquet文件到spark的内存,而hbase还需要同regionserver交互把数据传到spark的内存也是需要消耗时间的。总体来说,读parquet更快

hbase怎么查找本地文件?
在HBase中,可以通过使用Hadoop的分布式文件系统(HDFS)来存储数据,也可以使用本地文件系统来存储数据。如果需要在HBase中查找本地文件,可以使用HBase Shell或HBase Java API进行操作。
1. 在HBase Shell中查找本地文件:
可以使用HBase Shell的hadoop fs命令来查找本地文件,具体命令如下:
```
hadoop fs -ls file:///path/to/local/file
```
其中,/path/to/local/file是本地文件的路径。
2. 在HBase Java API中查找本地文件:
可以使用Hadoop的FileSystem API来访问本地文件系统,具体代码如下:
```
要在HBase中查找本地文件,您可以使用HBase的Java API和HBase的表。
首先,您需要创建一个HBase表,其中包含一个列族,用于存储文件的元数据。
然后,您可以使用HBase的Scan功能来扫描表,并使用过滤器来匹配文件的元数据。
一旦找到匹配的文件,您可以使用HBase的Get功能来获取文件的详细信息。
最后,您可以使用HBase的Java API来读取本地文件并进行进一步处理。这样,您就可以在HBase中查找本地文件。
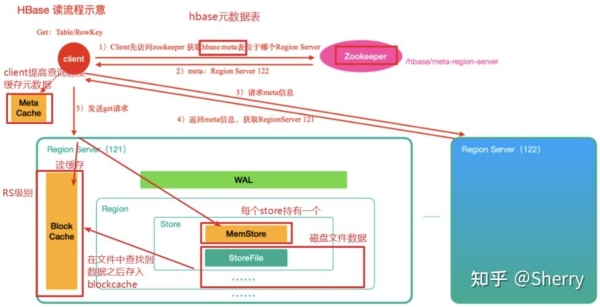
HBase怎么实现海量数据的毫秒级查询?
Base中单表的数据量通常可以达到TB级或PB级,但大多数情况下数据读取可以做到毫秒级。HBase是如何做到的哪?要想实现表中数据的快速访问,通用的做法是数据保持有序并尽可能的将数据保存在内存里。HBase也是这样实现的。
对于海量级的数据,首先要解决存储的问题。
数据存储上,HBase将表切分成小一点的数据单位region,托管到RegionServer上,和以前关系数据库分区表类似。但比关系数据库分区、分库易用。这一点在数据访问上,HBase对用户是透明的。
hbase是列式数据库吗?
hbase不是列式数据库。
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和即时查询。
相对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合于小批量的数据处理,常用于联机事务型数据处理。
HBase 既不像行式存储,又不像列式存储。它其实更像是面向列族的存储数据库。
到此,以上就是小编对于hbase查询很慢的问题就介绍到这了,希望介绍的4点解答对大家有用。
")
")
")
")



